

The Top Data Science Tools in 2025
Level up your Data game with the definitive list of Data Science tools in 2025
All Tools
 Fivetran
Fivetran

Key Features
- Prebuilt connectors to over 150 sources
- Automated schema management
- Continuous data sync
- Cloud-native architecture
- Centralized logging and monitoring
Fivetran is an automated data integration tool that helps data scientists consolidate data from multiple sources into a centralized data warehouse. It offers prebuilt connectors and manages schema changes automatically, which is crucial for ensuring up-to-date and accurate analyses. It's a hands-off solution for managing ETL/ELT pipelines.
 Alteryx Designer Cloud
Alteryx Designer Cloud
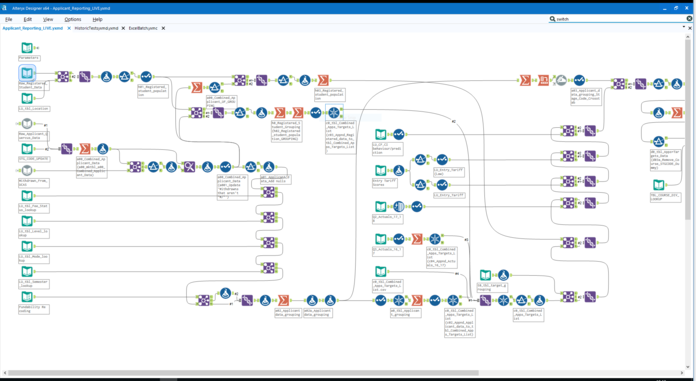
Key Features
- Smart suggestions for data cleaning
- Visual transformation workflows
- Data profiling and quality checks
- Connects to various data sources
- Integration with cloud and on-prem platforms
Alteryx Designer Cloud is a data wrangling tool that simplifies the process of cleaning, structuring and enriching raw data for analysis. It uses a guided, visual interface powered by intelligent suggestions, making it especially helpful for complex preprocessing tasks. Data scientists benefit from rapid transformation and profiling capabilities.
 BigQuery
BigQuery
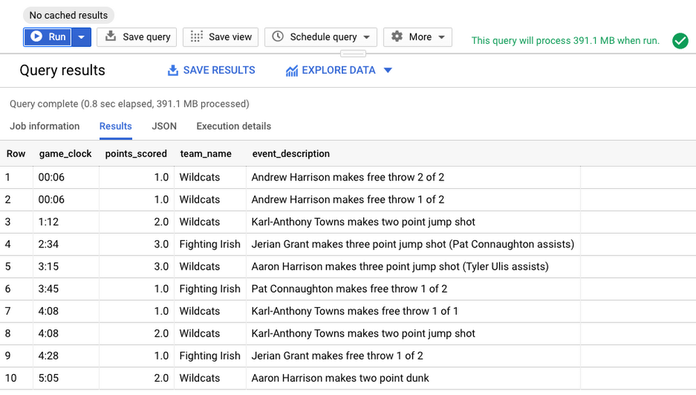
Key Features
- Fast SQL analytics on petabyte-scale data
- Serverless architecture
- Built-in machine learning with BigQuery ML
- Seamless GCP integration
- Real-time data processing
BigQuery is Google Cloud's fully-managed, serverless data warehouse optimized for fast SQL analytics on large datasets. It's ideal for data scientists handling massive datasets and needing high-performance querying capabilities. It integrates easily with other Google Cloud products and supports advanced analytics and ML.
 Airflow
Airflow
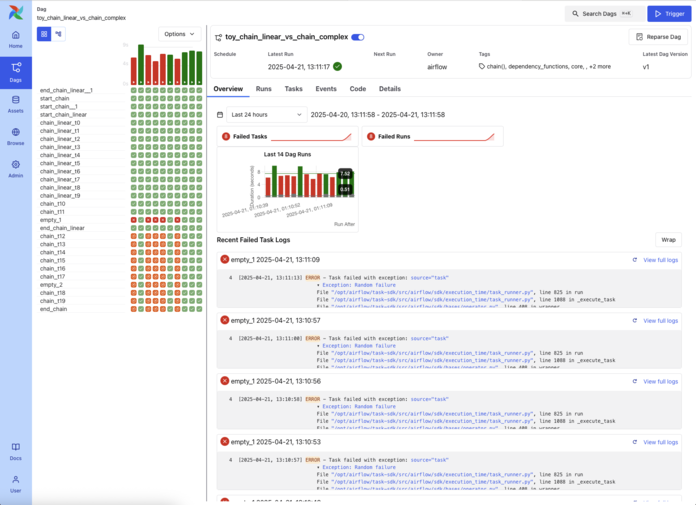
Key Features
- DAG-based workflow authoring
- Scheduler and monitoring UI
- Integration with many cloud providers
- Support for retries and alerting
- Scalable and extensible
Apache Airflow is an open-source platform used to programmatically author, schedule and monitor workflows. It's widely adopted by data scientists and engineers to orchestrate complex data pipelines. Airflow's DAG-based structure makes it ideal for managing ML workflows in production environments.
 Databricks
Databricks

Key Features
- Scalable Apache Spark engine
- Unified notebooks for Python, SQL, Scala
- MLflow for model tracking
- Real-time and batch processing
- Cloud-native and collaborative
Databricks is a unified analytics platform built on Apache Spark, offering collaborative environments for data science, engineering and business. It supports massive-scale data processing, ML training and real-time analytics. The platform integrates tightly with cloud storage and supports notebooks, SQL and MLflow.
 Snowflake
Snowflake
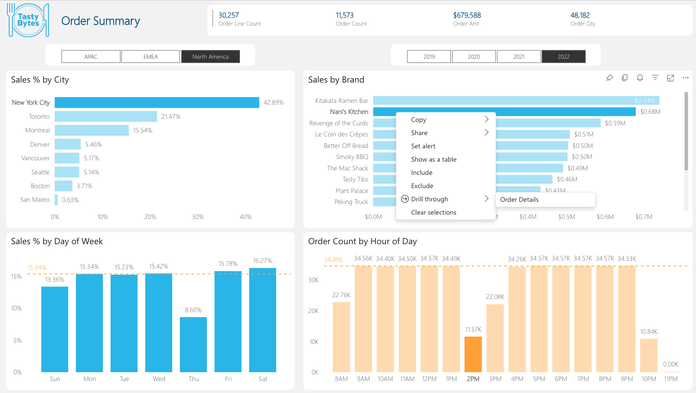
Key Features
- Scalable compute-storage separation
- Native support for structured and semi-structured data
- Secure data sharing across accounts
- Built-in machine learning support with Snowpark
- Integration with major cloud services
Snowflake is a cloud-based data platform that allows data scientists to store, query, and share large datasets with near-instantaneous scalability. Its architecture separates storage from compute, making it ideal for concurrent analytical workloads. With support for SQL, Python (via Snowpark), and integrations with BI tools, Snowflake is widely adopted in data-heavy organizations.
 KNIME
KNIME
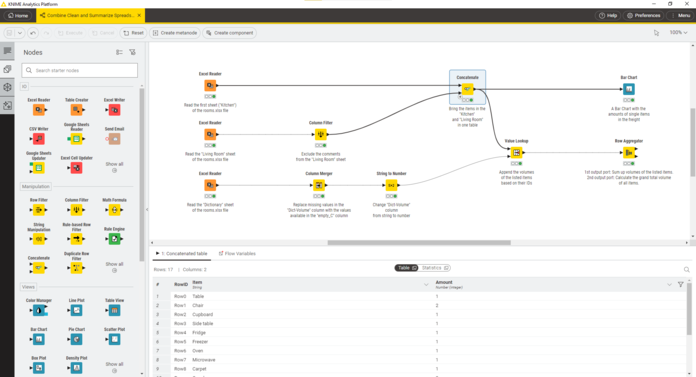
Key Features
- Visual workflow builder
- Built-in data mining and ML tools
- Connects to Python/R/Spark
- Scalable processing with KNIME Server
- Open-source and enterprise-ready
KNIME is an open-source analytics platform for creating data science workflows through visual programming. It supports a wide array of data wrangling, machine learning and modeling tools with minimal code. KNIME is suitable for both beginners and advanced users looking for customizable pipelines.
 Great Expectations
Great Expectations
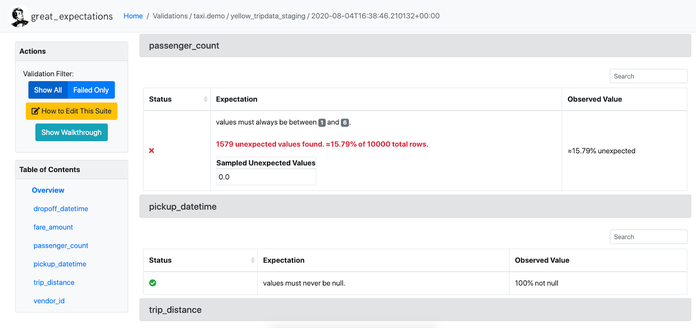
Key Features
- Data quality validation checks
- Automated documentation of data expectations
- Integration with Airflow, Spark, and Pandas
- Custom validation rules
- Test suite generation for data pipelines
Great Expectations is an open-source tool for validating, documenting and profiling data pipelines. It allows data scientists to create assertions about data quality, which helps ensure robust input for downstream models. The tool integrates well with modern data stacks and supports testing across environments.
 Deepnote
Deepnote
Key Features
- Real-time collaboration
- Integrates with Git, SQL, and cloud storage
- Interactive outputs and visualizations
- Role-based sharing and permissions
- Jupyter-compatible environment
Deepnote is a collaborative notebook designed for data science teams. It supports real-time editing, commenting and version control in a familiar notebook format. Unlike standard notebooks, Deepnote is built with collaboration and productivity features, making it ideal for cross-functional work.
 Altair RapidMiner
Altair RapidMiner
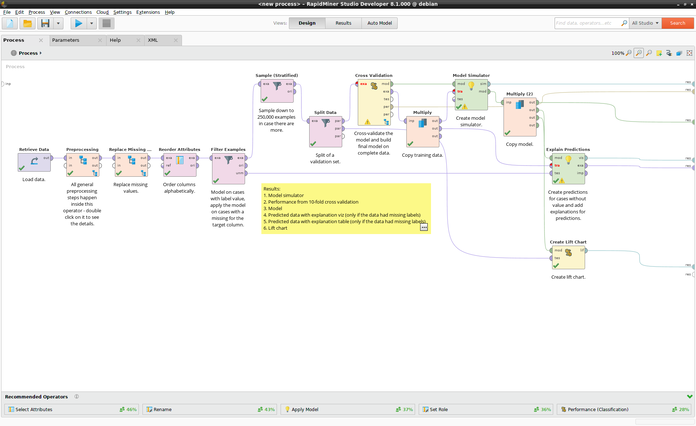
Key Features
- Visual drag-and-drop interface
- Extensive library of prebuilt algorithms
- Automated model validation
- Real-time scoring and deployment
- Team collaboration features
Altair RapidMiner is a data science platform aimed at accelerating the development and deployment of machine learning models through a visual workflow interface. It combines data preparation, modeling and deployment in a single tool. This is ideal for data scientists who prefer a low-code environment without compromising flexibility.
 Apache Superset
Apache Superset
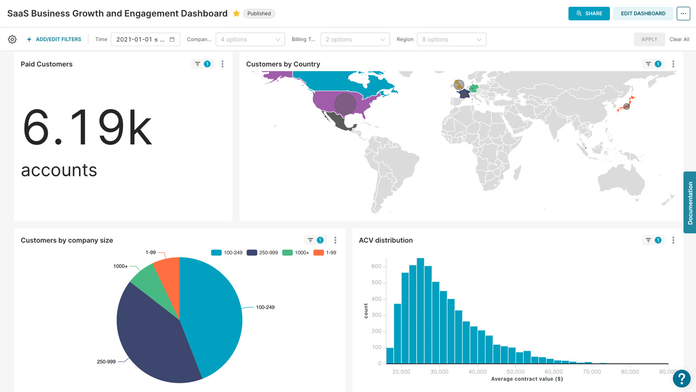
Key Features
- SQL-based data exploration
- Interactive dashboards
- Role-based access control
- Connects to most SQL-speaking databases
- Extensible with plugins and APIs
Apache Superset is an open-source data exploration and visualization tool designed for modern data workflows. It's especially useful for creating interactive dashboards and conducting data investigations without heavy coding. Superset supports large-scale data analysis through SQL and integrates with many databases.
 Jupyter Notebook
Jupyter Notebook
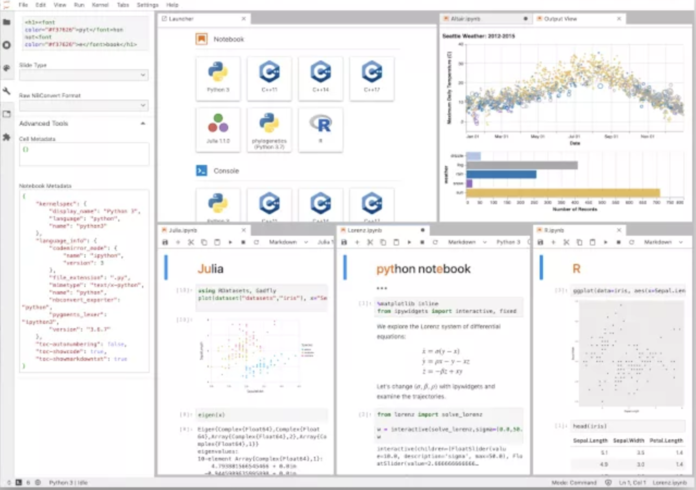
Key Features
- Interactive Python notebooks
- Supports multiple languages (via kernels)
- Inline visualization support
- Markdown for documentation
- Community extensions and plugins
Jupyter Notebook is a web-based interactive environment for writing and running code, equations, visualizations and narrative text. It's widely adopted in the data science community for its versatility and open-source nature. Jupyter supports numerous languages and is extensible via a rich ecosystem of plugins.
 Tableau Public
Tableau Public
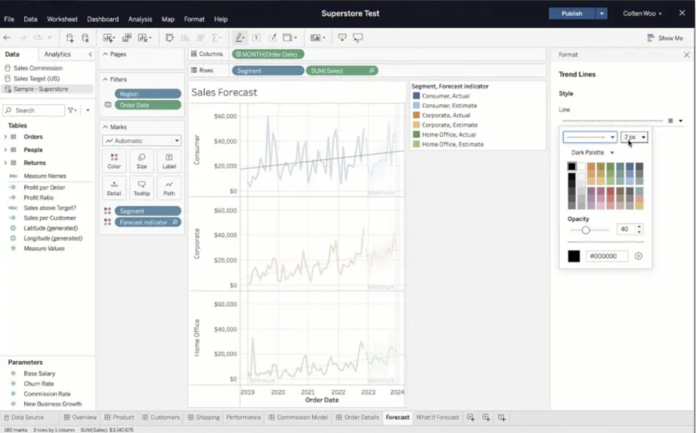
Key Features
- Interactive dashboard creation
- Public gallery of visualizations
- Connects to many data sources
- Custom calculated fields
- Drag-and-drop functionality
Tableau Public is a free platform for creating and sharing interactive data visualizations online. It's excellent for storytelling with data and is especially suited for analysts looking to publish work publicly. The drag-and-drop interface makes it accessible while still offering depth for complex visual analytics.
 YData Profiling
YData Profiling
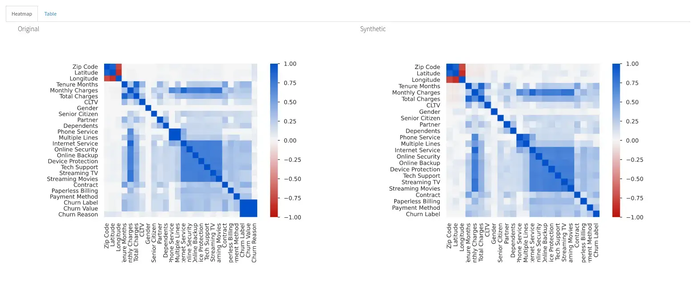
Key Features
- Automated EDA reports
- Correlation matrices and missing value maps
- Summary statistics for each variable
- Interactive HTML output
- Works directly with Pandas
YData Profiling is a Python library that generates EDA (exploratory data analysis) reports from a Pandas DataFrame with just a single line of code. It's invaluable for quickly understanding data distributions, correlations and quality. It's a must-have for early-stage data inspection.
 Looker (Google Cloud)
Looker (Google Cloud)
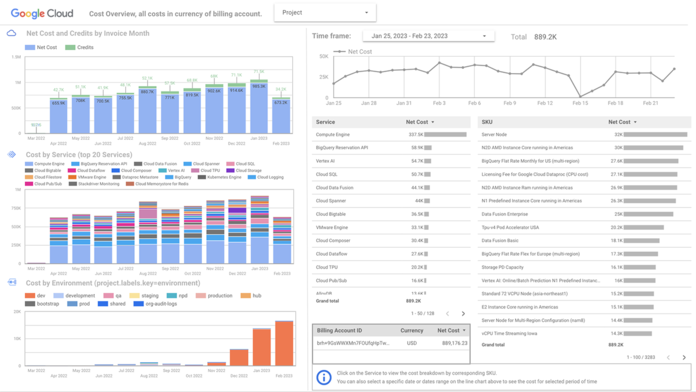
Key Features
- Real-time data exploration with LookML
- Embedded analytics and dashboards
- Data governance and version control
- Seamless Google Cloud integration
- Scheduled reporting and alerts
Looker is a modern data platform for business intelligence and analytics, now part of Google Cloud. It enables data scientists and analysts to create robust dashboards and explore datasets using a modeling language called LookML. It's highly customizable and integrates with various databases for real-time analytics.
 Hex
Hex
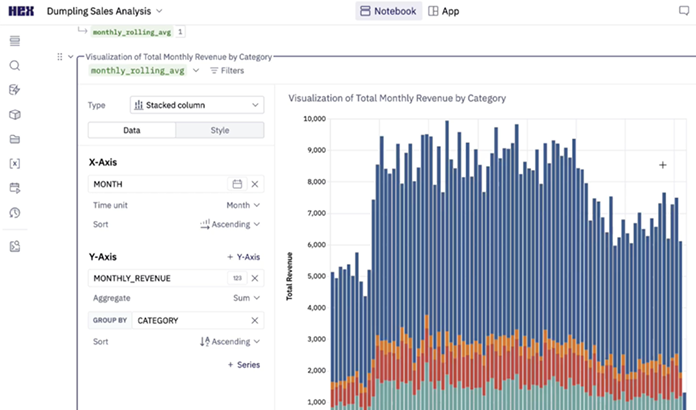
Key Features
- Live code cells for Python & SQL
- Interactive app-like dashboards
- Easy publishing and versioning
- Real-time collaboration
- Integration with databases and warehouses
Hex is a modern data platform for collaborative analytics and notebook-style workflows, built for data teams. It offers live Python, SQL and markdown cells in a single document, ideal for storytelling and analysis. Its publishing and sharing features make it easy to communicate insights within organizations.
 Sigma Computing
Sigma Computing
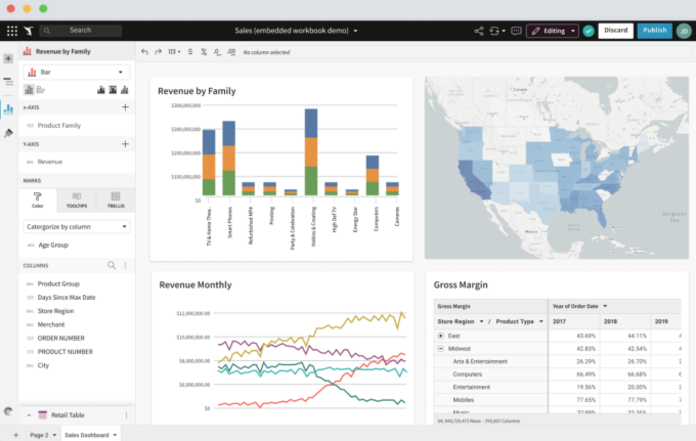
Key Features
- Spreadsheet interface with live SQL
- Real-time collaboration
- Native cloud data warehouse integration
- Visual exploration and dashboards
- Scalable cloud-based analytics
Sigma Computing provides a spreadsheet-like interface on top of cloud data warehouses, allowing data scientists and analysts to work in SQL and spreadsheets simultaneously. It democratizes data exploration while enabling powerful SQL queries and visualizations. It's optimized for cloud-scale analytics and team collaboration.
 Neptune.ai
Neptune.ai
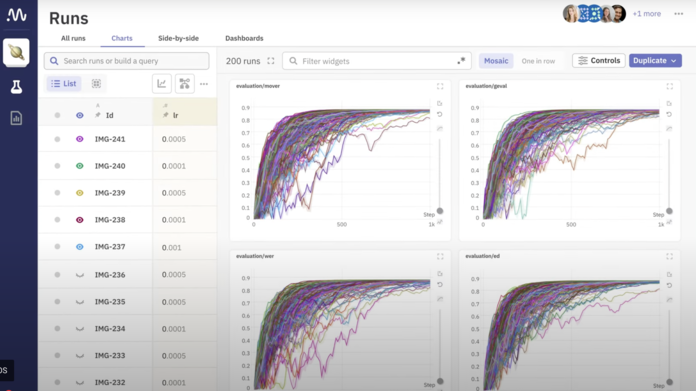
Key Features
- Track model training experiments
- Compare hyperparameters and metrics
- Visualize training curves and results
- Share projects across teams
- Lightweight integration with ML pipelines
Neptune.ai is a metadata store for MLOps, built to track, visualize and organize machine learning experiments. It's designed for teams needing model versioning, reproducibility and efficient collaboration. Neptune supports various ML frameworks and integrates into your existing pipelines.
 Google Colab
Google Colab
Key Features
- Free access to GPUs/TPUs
- Seamless integration with Google Drive
- Supports Python and major ML libraries
- Real-time collaboration
- No installation required
Google Colab is a cloud-based Jupyter notebook environment that allows you to write and execute Python code directly in your browser. It's ideal for machine learning, data analysis and deep learning tasks. With free access to GPUs and easy sharing capabilities, Colab can help you streamline collaborative and reproducible data science workflows.
 Kaggle
Kaggle
Key Features
- Public and private competitions
- Hosted notebooks with GPU support
- Extensive dataset repository
- Community forums and kernels
- Integration with Google Cloud
Kaggle is a platform offering datasets, code notebooks and competitions for data scientists at all skill levels. It's a great environment for learning new techniques, benchmarking models and engaging with a vibrant data science community. It also provides hosted Jupyter notebooks with GPU support and thousands of public datasets.
 AWS SageMaker
AWS SageMaker
Key Features
- Fully managed Jupyter notebooks
- Built-in AutoML capabilities
- Model hosting and A/B testing
- Ground Truth for labeling data
- Integrates with S3, EC2, and other AWS services
Amazon SageMaker is a comprehensive ML service that enables you to build, train and deploy machine learning models at scale. It's integrated with the AWS ecosystem and provides flexible infrastructure for data scientists to experiment and iterate. It also supports popular open-source frameworks like TensorFlow and PyTorch.
 Streamlit
Streamlit
Key Features
- Turn Python scripts into web apps
- Supports widgets and user inputs
- Real-time app updates
- Integrates with ML libraries (Pandas, TensorFlow)
- Open-source and lightweight
Streamlit is a Python-based app framework specifically built for machine learning and data science projects. It enables quick transformation of data scripts into interactive web apps with minimal code. Ideal for prototyping models and sharing insights interactively without needing frontend expertise.
 IBM Watson Studio
IBM Watson Studio
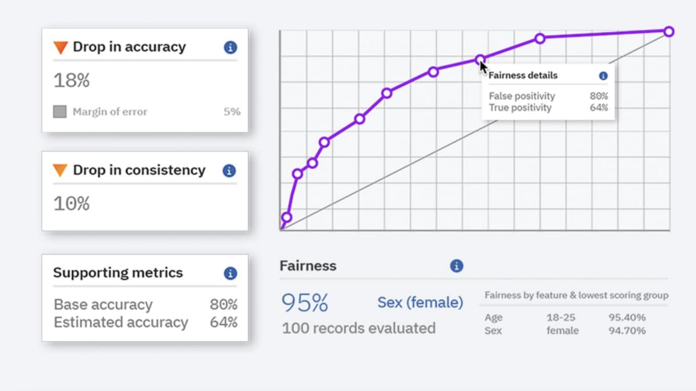
Key Features
- AutoAI for automated modeling
- Hosted Jupyter Notebooks
- Visual modeler interface
- Integration with IBM Cloud and Watson APIs
- Collaboration tools for teams
Watson Studio provides a suite of tools for building, training and managing AI models on the IBM Cloud. It supports both open-source and IBM-developed tools and enables collaborative, scalable workflows. Data scientists can leverage AutoAI, notebooks and model monitoring all in one platform.
 MLflow
MLflow
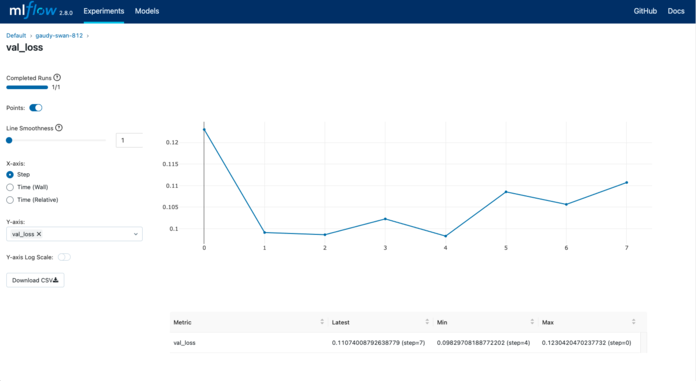
Key Features
- Track and log experiments
- Model packaging and reproducibility
- REST API for model serving
- Integration with major ML libraries
- Support for local and cloud deployment
MLflow is an open-source platform for managing the complete machine learning lifecycle, including experimentation, reproducibility and deployment. It's framework-agnostic, allowing data scientists to work across languages and environments. MLflow simplifies tracking experiments, packaging models and serving them in production.
Data Engineering & Integration
Fivetran
Key Features
- Prebuilt connectors to over 150 sources
- Automated schema management
- Continuous data sync
- Cloud-native architecture
- Centralized logging and monitoring
Fivetran is an automated data integration tool that helps data scientists consolidate data from multiple sources into a centralized data warehouse. It offers prebuilt connectors and manages schema changes automatically, which is crucial for ensuring up-to-date and accurate analyses. It's a hands-off solution for managing ETL/ELT pipelines.
Alteryx Designer Cloud
Key Features
- Smart suggestions for data cleaning
- Visual transformation workflows
- Data profiling and quality checks
- Connects to various data sources
- Integration with cloud and on-prem platforms
Alteryx Designer Cloud is a data wrangling tool that simplifies the process of cleaning, structuring and enriching raw data for analysis. It uses a guided, visual interface powered by intelligent suggestions, making it especially helpful for complex preprocessing tasks. Data scientists benefit from rapid transformation and profiling capabilities.
BigQuery
Key Features
- Fast SQL analytics on petabyte-scale data
- Serverless architecture
- Built-in machine learning with BigQuery ML
- Seamless GCP integration
- Real-time data processing
BigQuery is Google Cloud's fully-managed, serverless data warehouse optimized for fast SQL analytics on large datasets. It's ideal for data scientists handling massive datasets and needing high-performance querying capabilities. It integrates easily with other Google Cloud products and supports advanced analytics and ML.
Airflow
Key Features
- DAG-based workflow authoring
- Scheduler and monitoring UI
- Integration with many cloud providers
- Support for retries and alerting
- Scalable and extensible
Apache Airflow is an open-source platform used to programmatically author, schedule and monitor workflows. It's widely adopted by data scientists and engineers to orchestrate complex data pipelines. Airflow's DAG-based structure makes it ideal for managing ML workflows in production environments.
Databricks
Key Features
- Scalable Apache Spark engine
- Unified notebooks for Python, SQL, Scala
- MLflow for model tracking
- Real-time and batch processing
- Cloud-native and collaborative
Databricks is a unified analytics platform built on Apache Spark, offering collaborative environments for data science, engineering and business. It supports massive-scale data processing, ML training and real-time analytics. The platform integrates tightly with cloud storage and supports notebooks, SQL and MLflow.
Snowflake
Key Features
- Scalable compute-storage separation
- Native support for structured and semi-structured data
- Secure data sharing across accounts
- Built-in machine learning support with Snowpark
- Integration with major cloud services
Snowflake is a cloud-based data platform that allows data scientists to store, query, and share large datasets with near-instantaneous scalability. Its architecture separates storage from compute, making it ideal for concurrent analytical workloads. With support for SQL, Python (via Snowpark), and integrations with BI tools, Snowflake is widely adopted in data-heavy organizations.
KNIME
Key Features
- Visual workflow builder
- Built-in data mining and ML tools
- Connects to Python/R/Spark
- Scalable processing with KNIME Server
- Open-source and enterprise-ready
KNIME is an open-source analytics platform for creating data science workflows through visual programming. It supports a wide array of data wrangling, machine learning and modeling tools with minimal code. KNIME is suitable for both beginners and advanced users looking for customizable pipelines.
Great Expectations
Key Features
- Data quality validation checks
- Automated documentation of data expectations
- Integration with Airflow, Spark, and Pandas
- Custom validation rules
- Test suite generation for data pipelines
Great Expectations is an open-source tool for validating, documenting and profiling data pipelines. It allows data scientists to create assertions about data quality, which helps ensure robust input for downstream models. The tool integrates well with modern data stacks and supports testing across environments.
Data Analysis & Exploration
Deepnote
Key Features
- Real-time collaboration
- Integrates with Git, SQL, and cloud storage
- Interactive outputs and visualizations
- Role-based sharing and permissions
- Jupyter-compatible environment
Deepnote is a collaborative notebook designed for data science teams. It supports real-time editing, commenting and version control in a familiar notebook format. Unlike standard notebooks, Deepnote is built with collaboration and productivity features, making it ideal for cross-functional work.
Altair RapidMiner
Key Features
- Visual drag-and-drop interface
- Extensive library of prebuilt algorithms
- Automated model validation
- Real-time scoring and deployment
- Team collaboration features
Altair RapidMiner is a data science platform aimed at accelerating the development and deployment of machine learning models through a visual workflow interface. It combines data preparation, modeling and deployment in a single tool. This is ideal for data scientists who prefer a low-code environment without compromising flexibility.
Apache Superset
Key Features
- SQL-based data exploration
- Interactive dashboards
- Role-based access control
- Connects to most SQL-speaking databases
- Extensible with plugins and APIs
Apache Superset is an open-source data exploration and visualization tool designed for modern data workflows. It's especially useful for creating interactive dashboards and conducting data investigations without heavy coding. Superset supports large-scale data analysis through SQL and integrates with many databases.
Jupyter Notebook
Key Features
- Interactive Python notebooks
- Supports multiple languages (via kernels)
- Inline visualization support
- Markdown for documentation
- Community extensions and plugins
Jupyter Notebook is a web-based interactive environment for writing and running code, equations, visualizations and narrative text. It's widely adopted in the data science community for its versatility and open-source nature. Jupyter supports numerous languages and is extensible via a rich ecosystem of plugins.
Tableau Public
Key Features
- Interactive dashboard creation
- Public gallery of visualizations
- Connects to many data sources
- Custom calculated fields
- Drag-and-drop functionality
Tableau Public is a free platform for creating and sharing interactive data visualizations online. It's excellent for storytelling with data and is especially suited for analysts looking to publish work publicly. The drag-and-drop interface makes it accessible while still offering depth for complex visual analytics.
BigQuery
Key Features
- Fast SQL analytics on petabyte-scale data
- Serverless architecture
- Built-in machine learning with BigQuery ML
- Seamless GCP integration
- Real-time data processing
BigQuery is Google Cloud's fully-managed, serverless data warehouse optimized for fast SQL analytics on large datasets. It's ideal for data scientists handling massive datasets and needing high-performance querying capabilities. It integrates easily with other Google Cloud products and supports advanced analytics and ML.
YData Profiling
Key Features
- Automated EDA reports
- Correlation matrices and missing value maps
- Summary statistics for each variable
- Interactive HTML output
- Works directly with Pandas
YData Profiling is a Python library that generates EDA (exploratory data analysis) reports from a Pandas DataFrame with just a single line of code. It's invaluable for quickly understanding data distributions, correlations and quality. It's a must-have for early-stage data inspection.
Snowflake
Key Features
- Scalable compute-storage separation
- Native support for structured and semi-structured data
- Secure data sharing across accounts
- Built-in machine learning support with Snowpark
- Integration with major cloud services
Snowflake is a cloud-based data platform that allows data scientists to store, query, and share large datasets with near-instantaneous scalability. Its architecture separates storage from compute, making it ideal for concurrent analytical workloads. With support for SQL, Python (via Snowpark), and integrations with BI tools, Snowflake is widely adopted in data-heavy organizations.
Looker (Google Cloud)
Key Features
- Real-time data exploration with LookML
- Embedded analytics and dashboards
- Data governance and version control
- Seamless Google Cloud integration
- Scheduled reporting and alerts
Looker is a modern data platform for business intelligence and analytics, now part of Google Cloud. It enables data scientists and analysts to create robust dashboards and explore datasets using a modeling language called LookML. It's highly customizable and integrates with various databases for real-time analytics.
Hex
Key Features
- Live code cells for Python & SQL
- Interactive app-like dashboards
- Easy publishing and versioning
- Real-time collaboration
- Integration with databases and warehouses
Hex is a modern data platform for collaborative analytics and notebook-style workflows, built for data teams. It offers live Python, SQL and markdown cells in a single document, ideal for storytelling and analysis. Its publishing and sharing features make it easy to communicate insights within organizations.
Sigma Computing
Key Features
- Spreadsheet interface with live SQL
- Real-time collaboration
- Native cloud data warehouse integration
- Visual exploration and dashboards
- Scalable cloud-based analytics
Sigma Computing provides a spreadsheet-like interface on top of cloud data warehouses, allowing data scientists and analysts to work in SQL and spreadsheets simultaneously. It democratizes data exploration while enabling powerful SQL queries and visualizations. It's optimized for cloud-scale analytics and team collaboration.
KNIME
Key Features
- Visual workflow builder
- Built-in data mining and ML tools
- Connects to Python/R/Spark
- Scalable processing with KNIME Server
- Open-source and enterprise-ready
KNIME is an open-source analytics platform for creating data science workflows through visual programming. It supports a wide array of data wrangling, machine learning and modeling tools with minimal code. KNIME is suitable for both beginners and advanced users looking for customizable pipelines.
Machine Learning & Modeling
Neptune.ai
Key Features
- Track model training experiments
- Compare hyperparameters and metrics
- Visualize training curves and results
- Share projects across teams
- Lightweight integration with ML pipelines
Neptune.ai is a metadata store for MLOps, built to track, visualize and organize machine learning experiments. It's designed for teams needing model versioning, reproducibility and efficient collaboration. Neptune supports various ML frameworks and integrates into your existing pipelines.
Google Colab
Key Features
- Free access to GPUs/TPUs
- Seamless integration with Google Drive
- Supports Python and major ML libraries
- Real-time collaboration
- No installation required
Google Colab is a cloud-based Jupyter notebook environment that allows you to write and execute Python code directly in your browser. It's ideal for machine learning, data analysis and deep learning tasks. With free access to GPUs and easy sharing capabilities, Colab can help you streamline collaborative and reproducible data science workflows.
Kaggle
Key Features
- Public and private competitions
- Hosted notebooks with GPU support
- Extensive dataset repository
- Community forums and kernels
- Integration with Google Cloud
Kaggle is a platform offering datasets, code notebooks and competitions for data scientists at all skill levels. It's a great environment for learning new techniques, benchmarking models and engaging with a vibrant data science community. It also provides hosted Jupyter notebooks with GPU support and thousands of public datasets.
AWS SageMaker
Key Features
- Fully managed Jupyter notebooks
- Built-in AutoML capabilities
- Model hosting and A/B testing
- Ground Truth for labeling data
- Integrates with S3, EC2, and other AWS services
Amazon SageMaker is a comprehensive ML service that enables you to build, train and deploy machine learning models at scale. It's integrated with the AWS ecosystem and provides flexible infrastructure for data scientists to experiment and iterate. It also supports popular open-source frameworks like TensorFlow and PyTorch.
Altair RapidMiner
Key Features
- Visual drag-and-drop interface
- Extensive library of prebuilt algorithms
- Automated model validation
- Real-time scoring and deployment
- Team collaboration features
Altair RapidMiner is a data science platform aimed at accelerating the development and deployment of machine learning models through a visual workflow interface. It combines data preparation, modeling and deployment in a single tool. This is ideal for data scientists who prefer a low-code environment without compromising flexibility.
Streamlit
Key Features
- Turn Python scripts into web apps
- Supports widgets and user inputs
- Real-time app updates
- Integrates with ML libraries (Pandas, TensorFlow)
- Open-source and lightweight
Streamlit is a Python-based app framework specifically built for machine learning and data science projects. It enables quick transformation of data scripts into interactive web apps with minimal code. Ideal for prototyping models and sharing insights interactively without needing frontend expertise.
IBM Watson Studio
Key Features
- AutoAI for automated modeling
- Hosted Jupyter Notebooks
- Visual modeler interface
- Integration with IBM Cloud and Watson APIs
- Collaboration tools for teams
Watson Studio provides a suite of tools for building, training and managing AI models on the IBM Cloud. It supports both open-source and IBM-developed tools and enables collaborative, scalable workflows. Data scientists can leverage AutoAI, notebooks and model monitoring all in one platform.
Databricks
Key Features
- Scalable Apache Spark engine
- Unified notebooks for Python, SQL, Scala
- MLflow for model tracking
- Real-time and batch processing
- Cloud-native and collaborative
Databricks is a unified analytics platform built on Apache Spark, offering collaborative environments for data science, engineering and business. It supports massive-scale data processing, ML training and real-time analytics. The platform integrates tightly with cloud storage and supports notebooks, SQL and MLflow.
MLflow
Key Features
- Track and log experiments
- Model packaging and reproducibility
- REST API for model serving
- Integration with major ML libraries
- Support for local and cloud deployment
MLflow is an open-source platform for managing the complete machine learning lifecycle, including experimentation, reproducibility and deployment. It's framework-agnostic, allowing data scientists to work across languages and environments. MLflow simplifies tracking experiments, packaging models and serving them in production.
KNIME
Key Features
- Visual workflow builder
- Built-in data mining and ML tools
- Connects to Python/R/Spark
- Scalable processing with KNIME Server
- Open-source and enterprise-ready
KNIME is an open-source analytics platform for creating data science workflows through visual programming. It supports a wide array of data wrangling, machine learning and modeling tools with minimal code. KNIME is suitable for both beginners and advanced users looking for customizable pipelines.
MLOps & Deployment
Neptune.ai
Key Features
- Track model training experiments
- Compare hyperparameters and metrics
- Visualize training curves and results
- Share projects across teams
- Lightweight integration with ML pipelines
Neptune.ai is a metadata store for MLOps, built to track, visualize and organize machine learning experiments. It's designed for teams needing model versioning, reproducibility and efficient collaboration. Neptune supports various ML frameworks and integrates into your existing pipelines.
AWS SageMaker
Key Features
- Fully managed Jupyter notebooks
- Built-in AutoML capabilities
- Model hosting and A/B testing
- Ground Truth for labeling data
- Integrates with S3, EC2, and other AWS services
Amazon SageMaker is a comprehensive ML service that enables you to build, train and deploy machine learning models at scale. It's integrated with the AWS ecosystem and provides flexible infrastructure for data scientists to experiment and iterate. It also supports popular open-source frameworks like TensorFlow and PyTorch.
IBM Watson Studio
Key Features
- AutoAI for automated modeling
- Hosted Jupyter Notebooks
- Visual modeler interface
- Integration with IBM Cloud and Watson APIs
- Collaboration tools for teams
Watson Studio provides a suite of tools for building, training and managing AI models on the IBM Cloud. It supports both open-source and IBM-developed tools and enables collaborative, scalable workflows. Data scientists can leverage AutoAI, notebooks and model monitoring all in one platform.
Airflow
Key Features
- DAG-based workflow authoring
- Scheduler and monitoring UI
- Integration with many cloud providers
- Support for retries and alerting
- Scalable and extensible
Apache Airflow is an open-source platform used to programmatically author, schedule and monitor workflows. It's widely adopted by data scientists and engineers to orchestrate complex data pipelines. Airflow's DAG-based structure makes it ideal for managing ML workflows in production environments.
Databricks
Key Features
- Scalable Apache Spark engine
- Unified notebooks for Python, SQL, Scala
- MLflow for model tracking
- Real-time and batch processing
- Cloud-native and collaborative
Databricks is a unified analytics platform built on Apache Spark, offering collaborative environments for data science, engineering and business. It supports massive-scale data processing, ML training and real-time analytics. The platform integrates tightly with cloud storage and supports notebooks, SQL and MLflow.
MLflow
Key Features
- Track and log experiments
- Model packaging and reproducibility
- REST API for model serving
- Integration with major ML libraries
- Support for local and cloud deployment
MLflow is an open-source platform for managing the complete machine learning lifecycle, including experimentation, reproducibility and deployment. It's framework-agnostic, allowing data scientists to work across languages and environments. MLflow simplifies tracking experiments, packaging models and serving them in production.
Great Expectations
Key Features
- Data quality validation checks
- Automated documentation of data expectations
- Integration with Airflow, Spark, and Pandas
- Custom validation rules
- Test suite generation for data pipelines
Great Expectations is an open-source tool for validating, documenting and profiling data pipelines. It allows data scientists to create assertions about data quality, which helps ensure robust input for downstream models. The tool integrates well with modern data stacks and supports testing across environments.
Collaboration & Productivity
Deepnote
Key Features
- Real-time collaboration
- Integrates with Git, SQL, and cloud storage
- Interactive outputs and visualizations
- Role-based sharing and permissions
- Jupyter-compatible environment
Deepnote is a collaborative notebook designed for data science teams. It supports real-time editing, commenting and version control in a familiar notebook format. Unlike standard notebooks, Deepnote is built with collaboration and productivity features, making it ideal for cross-functional work.
Google Colab
Key Features
- Free access to GPUs/TPUs
- Seamless integration with Google Drive
- Supports Python and major ML libraries
- Real-time collaboration
- No installation required
Google Colab is a cloud-based Jupyter notebook environment that allows you to write and execute Python code directly in your browser. It's ideal for machine learning, data analysis and deep learning tasks. With free access to GPUs and easy sharing capabilities, Colab can help you streamline collaborative and reproducible data science workflows.
Kaggle
Key Features
- Public and private competitions
- Hosted notebooks with GPU support
- Extensive dataset repository
- Community forums and kernels
- Integration with Google Cloud
Kaggle is a platform offering datasets, code notebooks and competitions for data scientists at all skill levels. It's a great environment for learning new techniques, benchmarking models and engaging with a vibrant data science community. It also provides hosted Jupyter notebooks with GPU support and thousands of public datasets.
Jupyter Notebook
Key Features
- Interactive Python notebooks
- Supports multiple languages (via kernels)
- Inline visualization support
- Markdown for documentation
- Community extensions and plugins
Jupyter Notebook is a web-based interactive environment for writing and running code, equations, visualizations and narrative text. It's widely adopted in the data science community for its versatility and open-source nature. Jupyter supports numerous languages and is extensible via a rich ecosystem of plugins.
Streamlit
Key Features
- Turn Python scripts into web apps
- Supports widgets and user inputs
- Real-time app updates
- Integrates with ML libraries (Pandas, TensorFlow)
- Open-source and lightweight
Streamlit is a Python-based app framework specifically built for machine learning and data science projects. It enables quick transformation of data scripts into interactive web apps with minimal code. Ideal for prototyping models and sharing insights interactively without needing frontend expertise.
Hex
Key Features
- Live code cells for Python & SQL
- Interactive app-like dashboards
- Easy publishing and versioning
- Real-time collaboration
- Integration with databases and warehouses
Hex is a modern data platform for collaborative analytics and notebook-style workflows, built for data teams. It offers live Python, SQL and markdown cells in a single document, ideal for storytelling and analysis. Its publishing and sharing features make it easy to communicate insights within organizations.